Parser Formulae¶
Formulae are tools used by higher-level components of the parsing system. They take some data (typically some HTML or JSON) and return 0 to n strings. For our purposes, these strings will usually be tags, URLs, and timestamps. You will usually see them summarised with this panel:
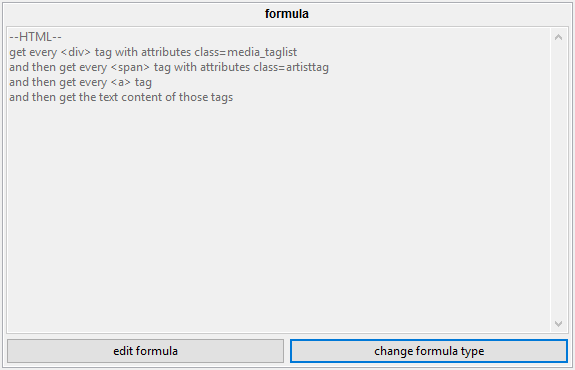
The different types are currently html, json, nested, zipper, and context variable.
html¶
This takes a full HTML document or a sample of HTML--and any regular sort of XML should also work. It starts at the root node and searches for lower nodes using one or more ordered rules based on tag name and attributes, and then returns string data from those final nodes.
For instance, if you have this:
<html>
<body>
<div class="media_taglist">
<span class="generaltag"><a href="(search page)">blonde hair</a> (3456)</span>
<span class="generaltag"><a href="(search page)">blue eyes</a> (4567)</span>
<span class="generaltag"><a href="(search page)">skirt</a> (5678)</span>
<span class="charactertag"><a href="(search page)">cool lady</a> (2345)</span>
<span class="artisttag"><a href="(search page)">cool artist</a> (123)</span>
</div>
<div class="content">
<span class="media">(a whole bunch of content that doesn't have any tag data)</span>
</div>
</body>
</html>
To find the "cool artist" creator tag here, you could:
- search beneath the root tag (
<html>) for the<div>tag with attributeclass="media_taglist" - search beneath that
<div>for<span>tags with attributeclass="artisttag" - search beneath those
<span>tags for<a>tags - and then get the string content of those
<a>tags
Changing the artisttag to charactertag or generaltag would give you cool lady or blonde hair, blue eyes, skirt respectively.
You might be tempted to just go straight for any <span> with class="artisttag", but many sites use the same class to render a sidebar of favourite/popular tags or some other sponsored content, so it is generally best to try to narrow down to a larger <div> container so you don't get anything you don't mean. Don't go crazy, but a little specificity is generally a good failsafe.
the ui¶
Clicking 'edit formula' on an HTML formula gives you this:
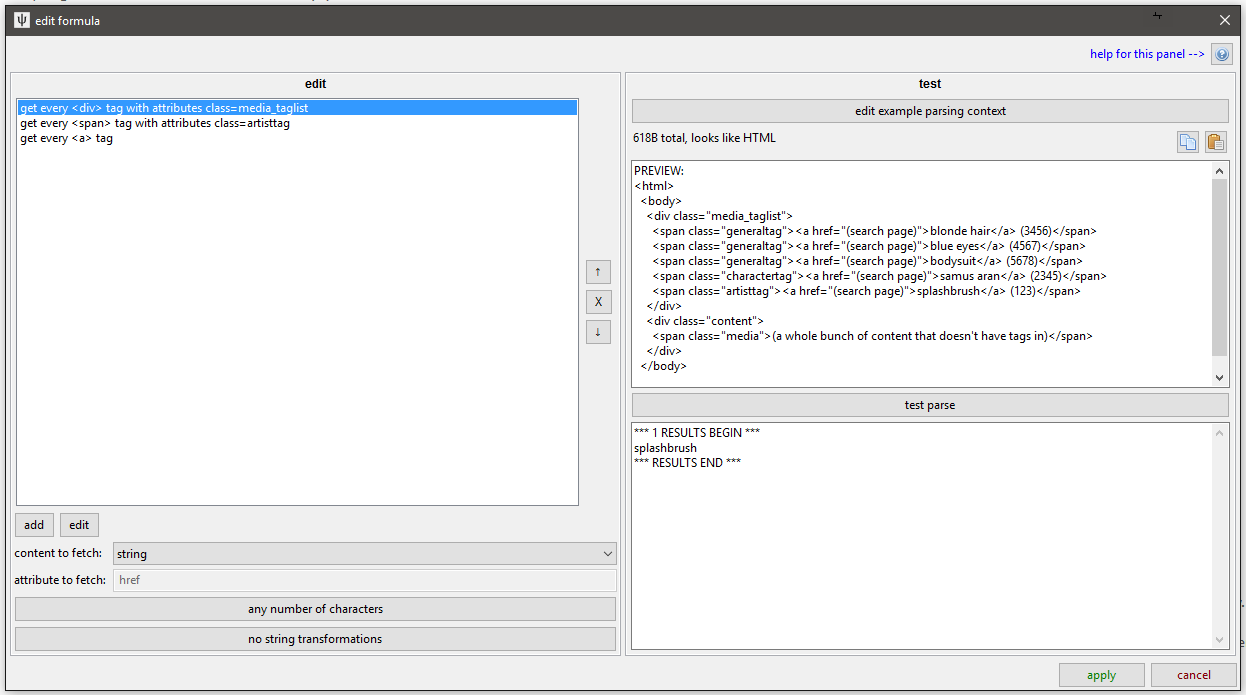
There's a bunch going on here, but the main split is that you edit on the left and test on the right. In this case, we have our three html parsing rules set up, and then underneath we say we want to fetch the 'string'. For an !#html <a> tag, we might want to fetch the href attribute.
Hydrus's powerful 'String Processing' system is also available. If you need to filter, convert, split, reorder, or otherwise munge the list of strings your formula gets, have a poke around here. Most formulae do not need any processing, but it is absolutely the way to get out of a tricky situation.
first, finding the right html tags¶
When you add or edit a tag search rule, you get this:
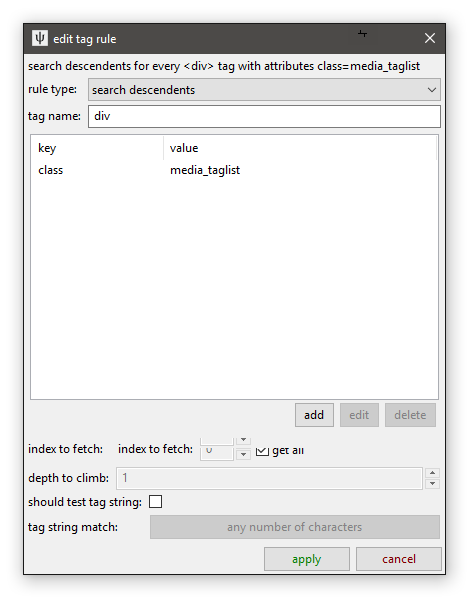
There is again a lot packed in here, but you'll typically be searching for a 'tag name' plus a 'class' or 'id' attribute.
Note that you can set it to fetch only the xth instance of a found tag, which can be useful in situations like this:
<span class="generaltag">
<a href="(add tag)">+</a>
<a href="(remove tag)">-</a>
<a href="(search page)">blonde hair</a> (3456)
</span>
Without any more attributes, there isn't a great way to distinguish the <a> with "blonde hair" from the other two--so just set get the 3rd <a> tag and you are good.
Most of the time, you'll be searching descendants (i.e. walking down the tree), but sometimes you might have this:
<span>
<a href="(link to post url)">
<img class="thumb" src="(thumbnail image)" />
</a>
</span>
There isn't a great way to find the <span> or the <a> when looking from above here, as they are lacking a class or id, but you can find the <img> ok, so if you find those and then add a rule where instead of searching descendants, you are 'walking back up ancestors' like this:
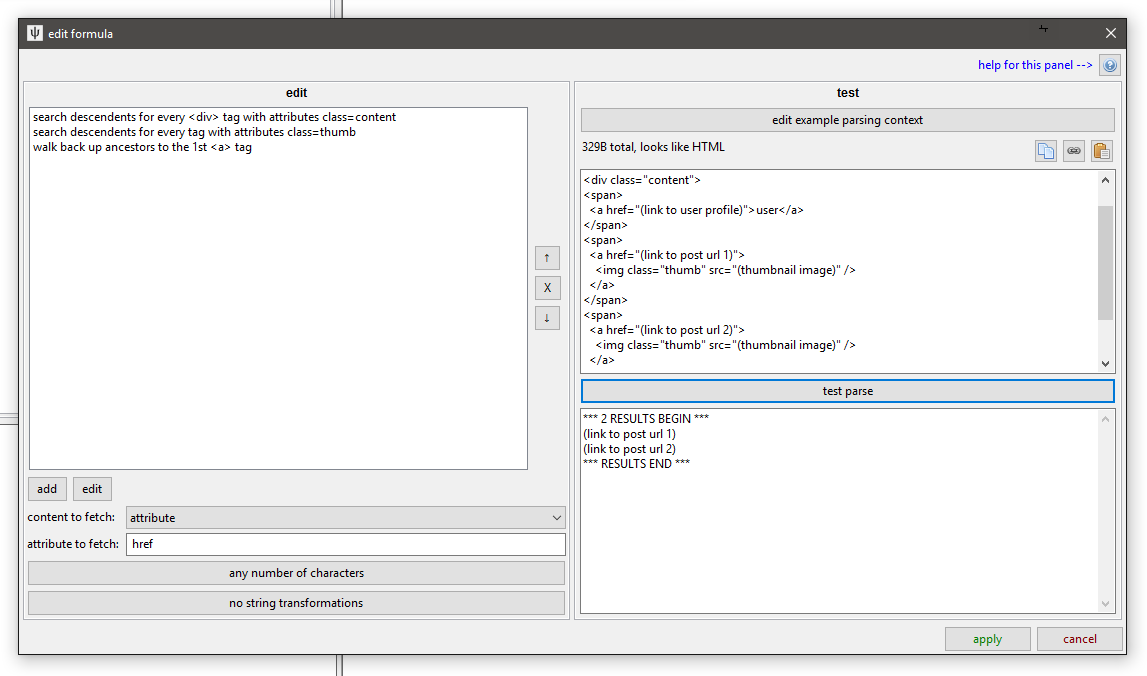
You can solve some tricky problems this way!
You can also set a String Match on the tag's string content. It tests its best guess at the tag's 'string' value, so you can find a tag with 'Original Image' as its text or that with a regex starts with 'Posted on: '. Have a play with it and you'll figure it out.
content to fetch¶
Once you have narrowed down the right nodes you want, you can decide what text to fetch. Given a node of:
<a href="(URL A)" class="thumb_title">Forest Glade</a>
Returning the href attribute would return the string "(URL A)", returning the string content would give "Forest Glade", and returning the full html would give <a href="(URL A)" class="thumb">Forest Glade</a>. This last choice is useful in complicated situations where you want a second, separated layer of parsing, which we will get to later.
string match and conversion¶
You can set a final String Match to filter the parsed results (e.g. "only allow strings that only contain numbers" or "only allow full URLs as based on (complicated regex)") and String Converter to edit it (e.g. "remove the first three characters of whatever you find" or "decode from base64").
testing¶
The testing panel on the right is important and worth using. Copy the html from the source you want to parse and then hit the paste buttons to set that as the data to test with. The larger panels of the parsing system pass their test data on to their children, so it is usually good to do one fetch at the 'edit parser' level to populate the test data for all your content parsers and formulae you then go into.
json¶
This takes some JSON and does a similar style of search:
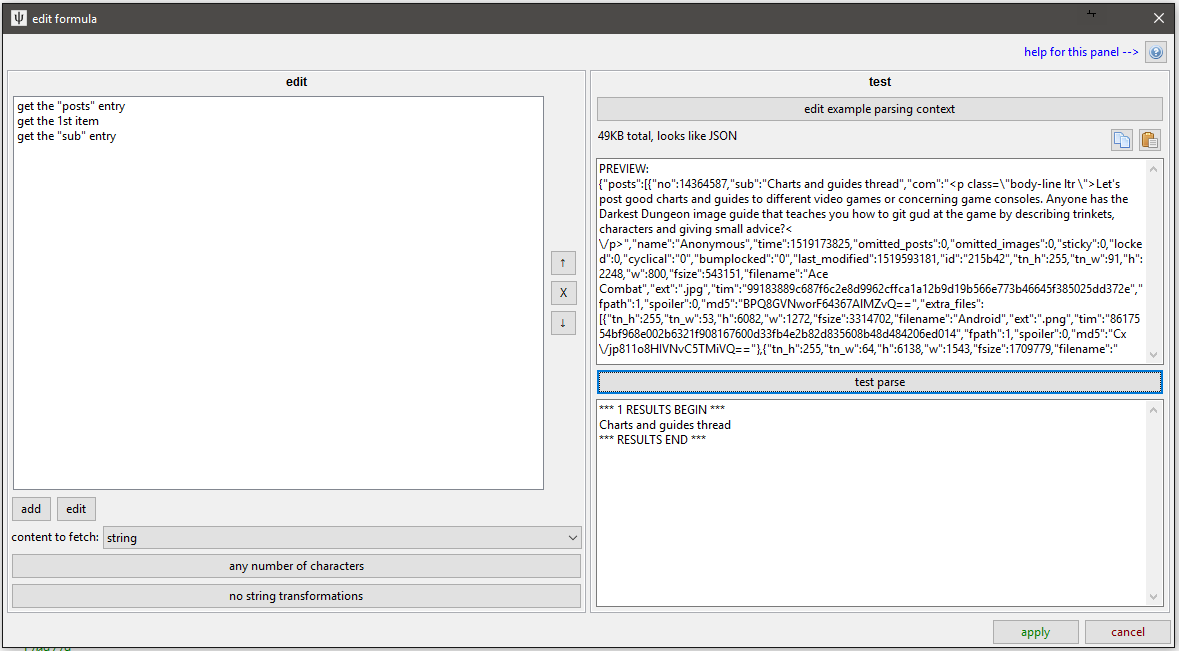
It is a bit simpler than HTML--if the current node is a list (called an 'Array' in JSON), you can fetch every item or the xth item, and if it is a dictionary (called an 'Object' in JSON), you can fetch a particular entry by name. Since you can't jump down several layers with attribute lookups or tag names like with HTML, you have to go down every layer one at a time. In any case, if you have something like this:
Note
It is a great idea to check the html or json you are trying to parse with your browser. Most web browsers have excellent developer tools that let you walk through the nodes of the document super easily, much better than my ugly UI. This image is one of the views Firefox provides if you simply enter a JSON URL.
Searching for "posts"->1st list item->"sub" on this data will give you "Nobody like kino here.".
Searching for "posts"->all list items->"tim" will give you the three SHA256 file hashes (since the third post has no file attached and so no 'tim' entry, the parser skips over it without complaint).
Searching for "posts"->1st list item->"com" will give you the OP's comment, ~AS RAW UNPARSED HTML~.
The default is to fetch the final nodes' 'data content', which means coercing simple variables into strings. If the current node is a list or dict, no string is returned.
But if you like, you can return the json beneath the current node (which, like HTML, includes the current node). This again will come in useful later.
nested¶
If you want to parse some JSON that is tucked inside an HTML attribute, or vice versa, use a nested formula. This parses the text using one formula type and then passes the result(s) to another.
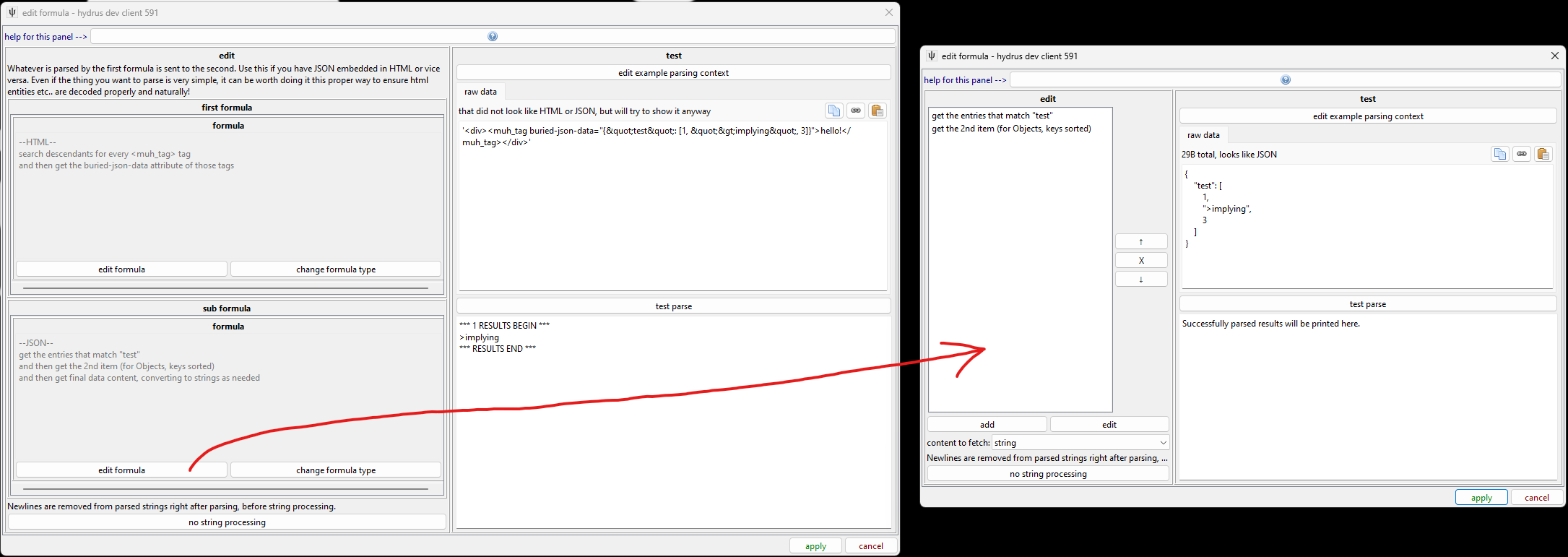
The especially neat thing about this is the encoded characters like > or escaped JSON characters are all handled natively for you. Before we had this, we had to hack our way around with crazy regex.
zipper¶
If you want to combine strings from the results of different parsers--for instance by joining the 'tim' and the 'ext' in our json example--you can use a Zipper formula. This fetches multiple lists of strings and zips their result rows together using \1 regex substitution syntax:
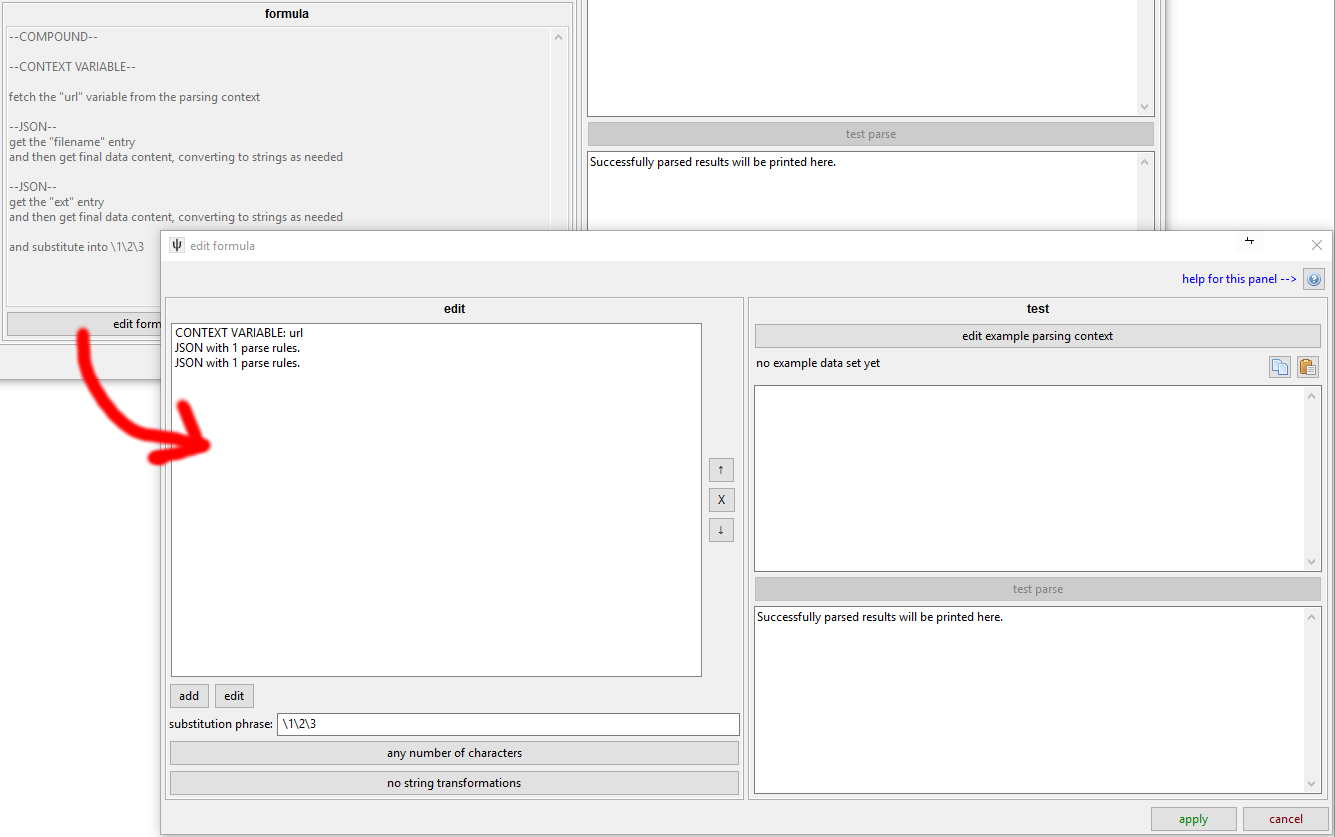
This is a complicated example taken from one of my thread parsers. I have to take a modified version of the original thread URL (the first rule, so \1) and then append the filename (\2) and its extension (\3) on the end to get the final file URL of a post. You can mix in more characters in the substitution phrase, like \1.jpg or even have multiple instances (https://\2.muhsite.com/\2/\1), if that is appropriate.
If your sub-formulae produce multiple results, the Zipper will produce that many also, iterating the sub-lists together.
If parser 1 gives:
a
b
c
And parser 2 gives:
1
2
3
Using a substitution phrase of "\1-\2" will give:
a-1
b-2
c-3
If one of the sub-formulae produces fewer results than the others, its final value will be used to fill in the gaps. In this way, you might somewhere parse one prefix and seven suffixes, where joining them will use the same prefix seven times.
static¶
This makes it simple to output any text you want. If you want to pre-bake a tag into a parser, or you need a base to do some funky string conversion on, this will do it.
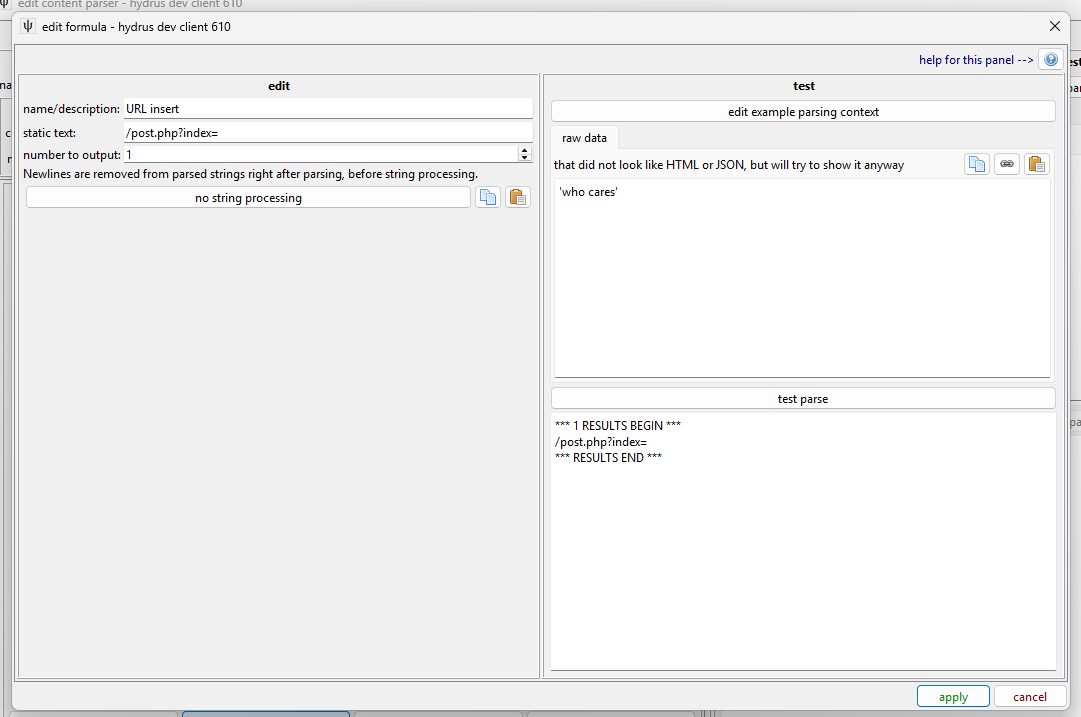
You can also have it output that same text multiple times, if that is convenient.
context variable¶
This is a basic hacky answer to a particular problem. It is a simple key:value dictionary that at the moment only stores one variable, 'url', which contains the original URL used to fetch the data being parsed.
If a different URL Class links to this parser via an API URL, this 'url' variable will always be the API URL (i.e. it literally is the URL used to fetch the data), not any thread/whatever URL the user entered.
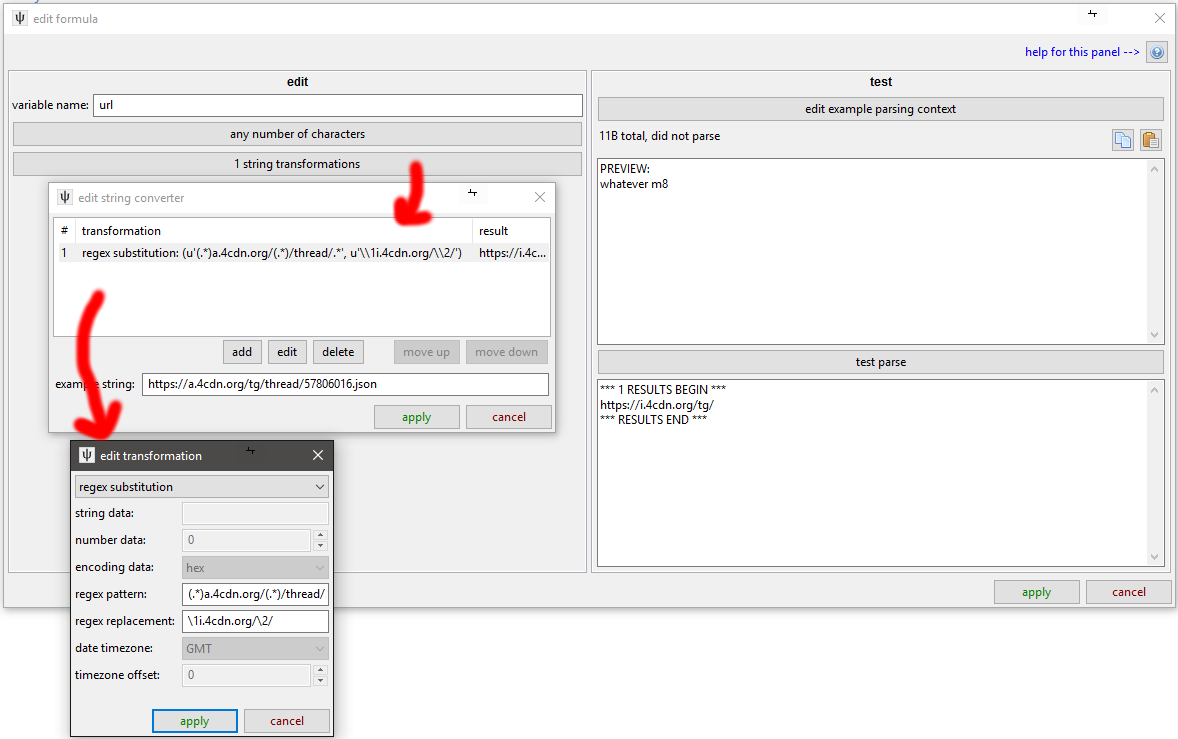
Hit the 'edit example parsing context' to change the URL used for testing.
If you want to make some parsers, you will have to get familiar with how different sites store and present their data!